Notes on X12
Russell Bateman
February 2023
| |
Notes on X12Russell Bateman |
Getting back into X12...
X12 is an ANSI standard for data-exchange of electronic-data exchange (EDI) as used in purchase orders, invoices, shipping status, payment information, etc., and, particularly in my interest, healthcare claims passed between providers and Medicare or other health care plans.
I'm only going to concentrate on this particular consumption of X12.
837 is an electronic file containing patient-claim information and is submitted to an insurance company instead of paper.
Also, ...
835 is an electronic file documenting the funds transfer, how the claim is paid or denied. Pairing the 835 remittance advice against its 837 claim data can add a dimension of clarity.
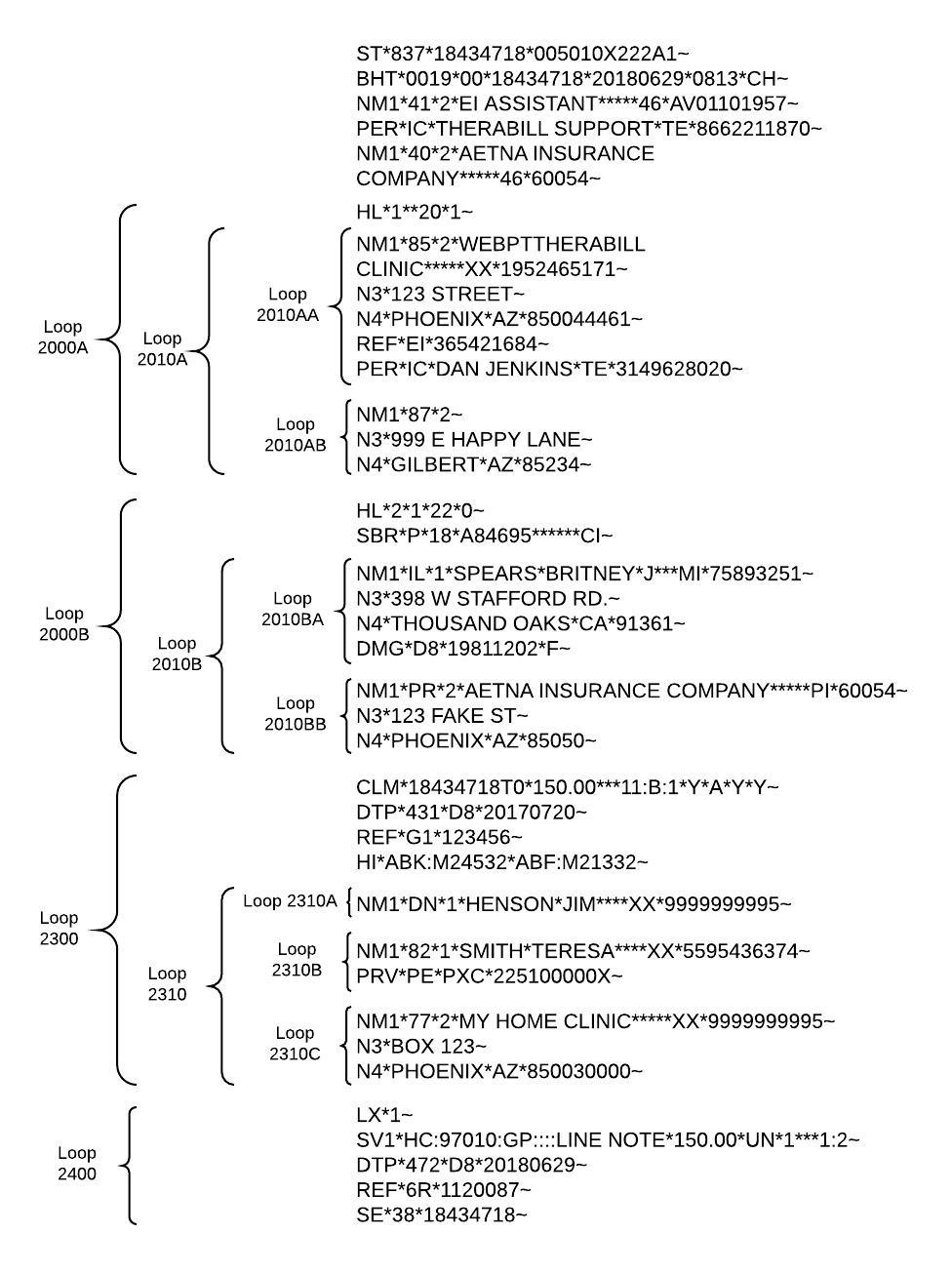
In an 837, there are
(Note that Yarsquidy supports classes for each of these.)
A block or section of an EDI files is called a loop. Loops are the biggest component in an EDI, but often the hardest to distinguish. They typically begin with an HL or NMI segment. When there are multiple loops, they're usually broken into 5 main sections:
(This is the basic format of an EDI for a primary payer, but some payers have very specific requirements that cause additional loops and segment to be included.)

Each loop contains multiple (different) segments. The following codes are commonly seen:
| PRV (provider) | SBR (subscriber) | HL (hieracrchy) |
| NM1 (name) | N3 (street) | N4 (city, state, zip) |
| DTP (date) | DMG (demographic) | REF (reference) |
| CLM (claim) | LX (line) | SV1 (service) |
| ST (transaction set) |
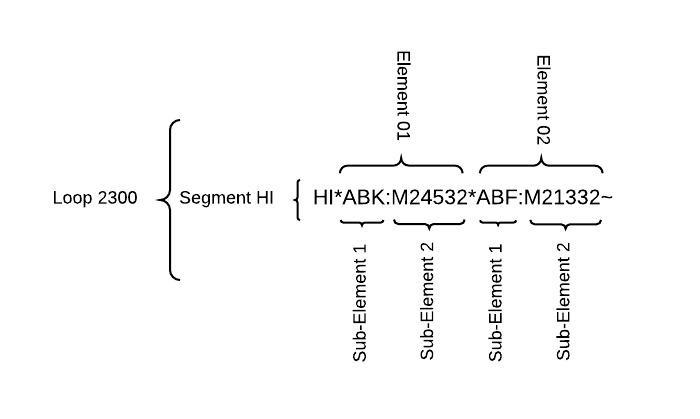
Within each segment appear many asterisks (*) which, like the pipe character (|) in HL7v2, separate elements of that segment. Also, the colon (:) is used to separate subelements.
Elements and subelements are introduced by a segment-identifier code, in this illustration, one of:
An 837 contains patient claim information. This file is submitted to an insurance company or a clearinghouse.
Formats are three:
837 files are broken down into loops, segments and elements. Each loop, segment and element contains specific information.
Loops are difficult to distinguish. Normally, they begin with NM or HL segments. There are multiple types, but they are all broken down into 5 primary sections:
| 2000A | Billing provider |
| 2000B | Subscriber |
| 2000C | Client, if different from the subscriber |
| 2300 | Claim information |
| 2400 | Service line information |
Here are common ones:
| SV1 | Service |
| PRV | Provider |
| LX | Line |
| SBR | Subscriber |
| CLM | Claim |
| HL | Hierarchy |
| REF | Reference |
| NM1 | Name |
| DMG | Demographic |
| N3 | Street address |
| N4 | City, state, and zipcode |
| DTP | Date |
Generally separated by asterisks while subelements within are separated by colons. Common elements:
| ABF | Diagnosis |
| 41 | Claim creator |
| ABK | Principal diagnosis |
| 40 | Claim receiver |
| HC | Standard CPT code |
| 85 | Bill provider |
| Y4 | Claim casualty number |
| 82 | Rendering provider |
| XX | NPI |
| DN | Referring provider |
| EI | EIN or tax id |
| IC | Information contact |
| SY | Social Security Number |
| 472 | Date of service |
| 77 | Service location |
...I'm using to read and understand health care EDI. This parser was once also called, X12Simple.
The Yarsquidy X12 parser library handles all of X12, but we're more interested here in looking at it from the perspective of EDI (837). The latest version I have found is 2.0.0. It carries an Apache license.
The first version of this parser was v0.9 (16 April 2011), the documented version v1.0 (21 May 2013) and the latest version known in 2023 was v2.0.0 from 2016.
The PDF documentation gives a date of 31 January 2016, but claims to cover v1.0.
There are a source- and javadoc JARs in the Huawei Cloud at https://mirrors.huaweicloud.com/repository/maven/com/yarsquidy/x12-parser/2.0.0/.
<dependency> <groupId>com.yarsquidy</groupId> <artifactId>x12-parser</artifactId> <version>2.0.0</version> </dependency>
See page 3 of X12-Parser Documentation, release 1.0.1 by Prasad Balan and Ryan Colewell, 31 January 2016.
Some of what's below is robbed from the document, some is based on personal observation, some is pure speculation waiting to be verified by personal experience.
| Classname | Notes |
|---|---|
| Cf | —the configuration element that represents, because you configure it (which is very complicated to do), items required to identify a loop in an X12 transaction. Some loops are identified only by segment id while others require a segment id plus additional qualifiers. |
| Context | —represents an X12 context consisting of a segment separator, an element separator and a composite-element separator. (Like HL7 v2, separating characters can be defined. In X12, they are frequently the asterisk just as in HL7 v2, they are most often the vertical bar.) The context of an X12 message is done when instantiating the configuration element (Cf). |
| Loop | —represents a loop in an ANSI X12 transaction; this has
special meaning connected to the type of an X12 transaction.
Loops consist of
|
| Segment | —a segment is an aggregation of elements (just as in
HL7 v2). It appears as a line when illustrated for human readability.
Segments are grouped (as a list) in loops, each consisting of
|
| Element | —a formal name for what is only String in Java. Some elements are also subelements. You don't get that parse for free, however. |
| validation | Unlike many other frameworks (HAPI v2, MDHT, HAPI FHIR),
Yarsquidy cannot validate an X12 transaction. Parsing produces
|
As nearly as I can tell, this parser offers the advantage of predefining what, for its Cf instantiation, Yarsquidy requires skill and expertise. Generative, this parser will also aid in creating and writing an X12 file (but we don't need to do that and maybe Yarsquidy can do that too).
<dependency> <groupId>com.imsweb</groupId> <artifactId>x12-parser</artifactId> <version>1.15</version> </dependency>
We're going to peruse the documentation at imsweb / x12-parser.
This parser, requiring Java 8 or later, claims to support parsing of:
To process an X12 file:
X12Reader reader = new X12Reader( FileType.ANSI837_5010_X222, new File( "/path/file.txt" ) );
Accessing data... you can even access data arbitrarily deep down inside X12:
List< Loop > loops = reader.getLoops();
String data = loop.getLoop( "ISA_LOOP" )
.getLoop( "GS_LOOP" ) // subloop of ISA_LOOP
.getLoop( "ST_LOOP" ) // subloop of GS_LOOP
.getLoop( "1000A" )
.getSegment( "NM1" ) // segment of loop 1000A
.getElement( "NM101" ) // first element of segment NM1
.getSubElement( 1 ); // first subelement in NM101
Should loops or segments repeat (as they can), it's possible to access any particular one:
Loop loop = loop.getLoop( "1000A", 1 ); Segment segment = loop.getSegment( "NM1", 2 );
Search for all loops with an id of 1000B in the 1000A loop even if it occurs deep down in the loop:
Loop loop = loop.getLoop( "1000A" ); List< Loop > loops = loop.findLoop( "1000B" );
The same thing can be done for segments.